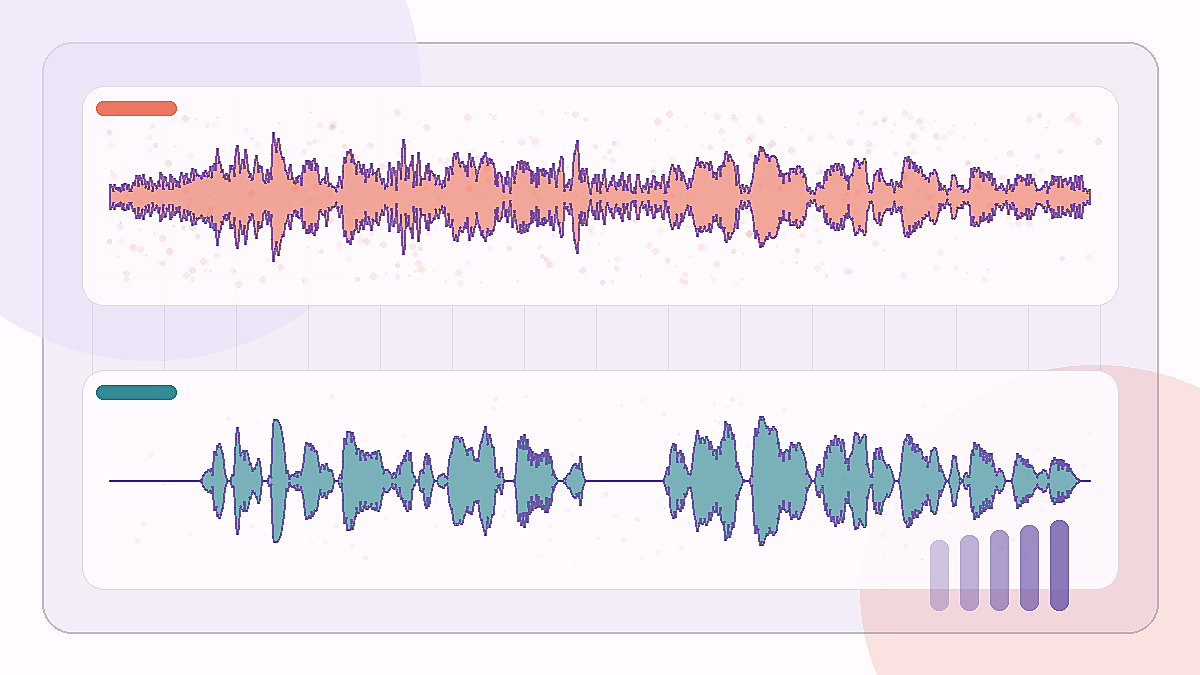
SNR-winst: +15.0 dB
Spraak met busgeluid opschonen
Een busfragment met lage SNR waarin verkeersachtig gerommel onder de gesproken zin ligt.
Rumoerige bron
Geïsoleerde stem
Edinburgh noisy speech · bus 2.5 dB
Heb je een interview, gesprek, college, podcastclip, veldopname of spraakmemo waarin spraak moeilijk te horen is? Upload de audio en isoleer de gesproken stem naar een schonere MP3.
Een voice isolator scheidt menselijke spraak van achtergrondgeluid in een audio-opname. Gebruik het voor gesproken stem in interviews, gesprekken, colleges, podcasts, veldopnames of spraakmemo’s. Gebruik voor songs en muziekzang Vocal Remover of Stem Splitter.
Gebruik voor songs en muziekzang Vocal Remover / Stem Splitter
Alleen audio-upload. 3 gratis minuten voor in aanmerking komende accounts. Credits worden terugbetaald als providerverwerking mislukt.
Log in om audio te verwerken
Je kunt hier een bestand kiezen en vooraf beluisteren, maar de Voice Isolator-taak start pas na inloggen omdat betaalde GPU-verwerking wordt gebruikt.
Originele rumoerige opname
Geïsoleerde gesproken stem
Vier korte noisy-speech-fragmenten zijn verwerkt met playmore/speech-enhancer op Replicate. Speel elk before/after-paar af om de opschoning te beoordelen.
Een busfragment met lage SNR waarin verkeersachtig gerommel onder de gesproken zin ligt.
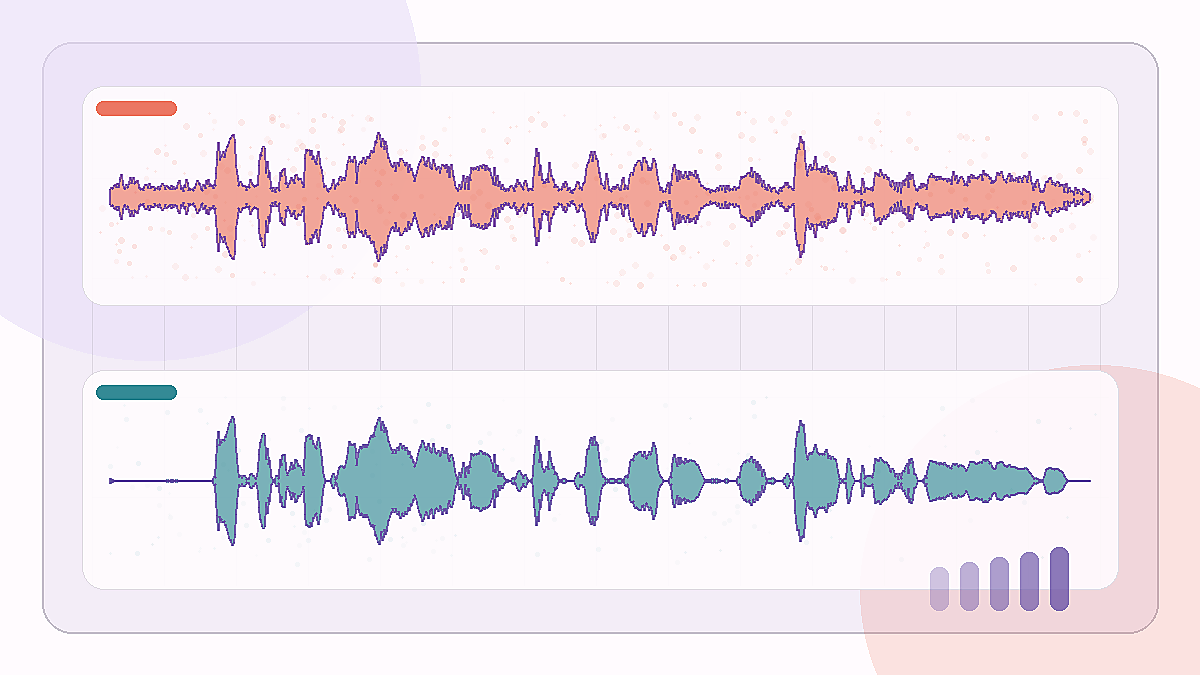
Een café-achtergrondsample dat test of spraak verstaanbaar blijft nadat brede omgevingsruis is verminderd.
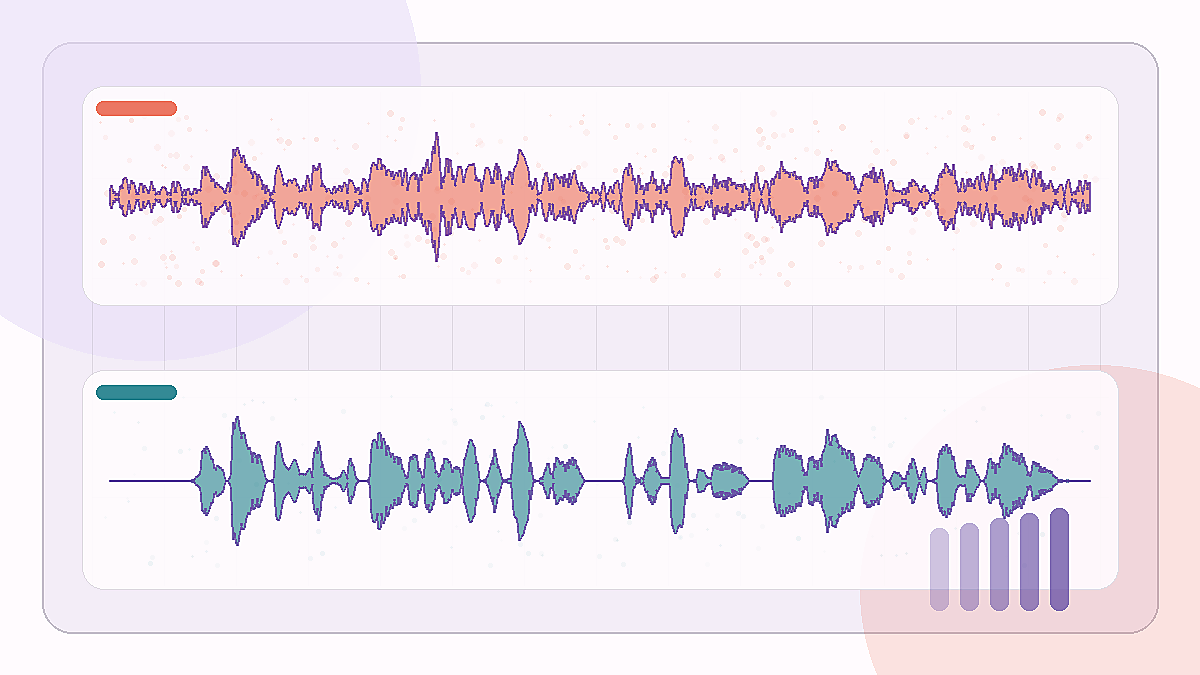
Een lastige kantooropname waarbij de zin behouden blijft terwijl kamergeluid wordt teruggedrongen.
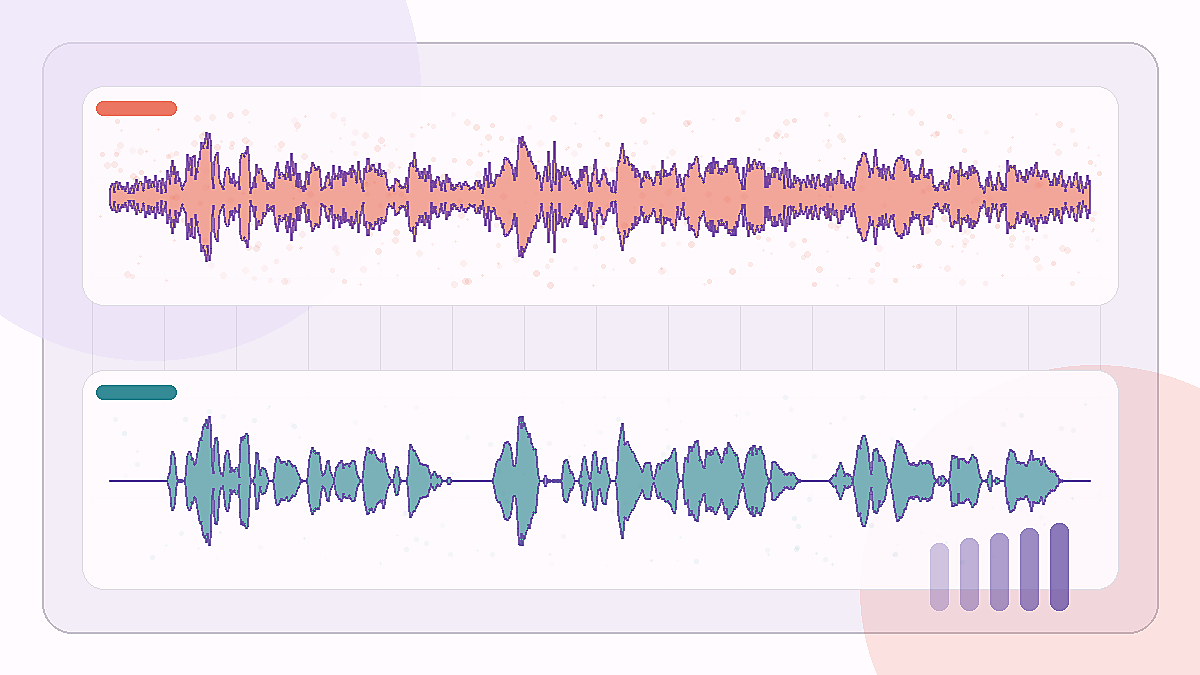
Een langer fragment van een openbaar plein met veel achtergrondgeluid rond één gesproken stem.
Audiobron: Cassia Valentini-Botinhao, Noisy speech database for training speech enhancement algorithms and TTS models, University of Edinburgh DataShare, CC BY 4.0. De verbeterde uitvoer is gegenereerd met Replicate playmore/speech-enhancer.
Voice-isolator-zoekopdrachten mengen twee taken: spraak opschonen en muziekzang verwijderen. Deze pagina is voor gesproken stem in rumoerige opnames. Is je bron een song, karaoke-track, acapella-verzoek of muziekzang, gebruik dan Vocal Remover.
Begin met een audiobestand: MP3, WAV, FLAC, M4A, AAC, OGG of WEBM. Voice Isolator v1 accepteert bestanden tot 50 MB en 600 seconden. Directe MP4-upload, URL ophalen en live microfoon-cleanup vallen buiten deze workflow.
Spraak opschonen moet hoorbaar zijn. Gebruik de voor-speler voor je originele rumoerige opname en vergelijk die na verwerking met de geïsoleerde gesproken stem. Die vergelijking helpt bij verstaanbaarheid, artefacten en downloadgereedheid.
Het resultaat is één MP3 voor de gesproken stem, geen stem-pakket, mixer-sessie of ZIP-bestand. Gebruik het voor review, montage, transcriptievoorbereiding, podcast-cleanup of een duidelijkere versie van een spraakopname.
Je kunt op de pagina een bestand kiezen en beluisteren, maar de kostbare taak start na inloggen. Voice Isolator gebruikt 1 credit per bronseconde. Providerindiening, providerfout en outputfinalisatie betalen credits terug.
Voice Isolator is geen realtime ruisonderdrukking voor calls, OBS, Discord, Zoom of Teams. Het is geen diarization, doelsprekerextractie, forensic restoration of scheiding van overlappende sprekers. Extraheer bij video eerst audio en upload die.
Deze flow staat los van de muziek-stem-splitter. Hij stuurt de geüploade audio naar Replicate playmore/speech-enhancer met het mossformer2_se_48k model en finaliseert de output als isolated-voice MP3 voor download.
Voice Isolator haalt gesproken stem uit rumoerige opnames zoals interviews, gesprekken, colleges, podcasts, spraakmemo’s en veldopnames. Het is spraak-cleanup, geen muziek-stem separation.
Nee. Deze pagina is voor gesproken stem in rumoerige opnames. Voor songs, muziekzang, karaoke, acapella, remix of stem-workflows gebruik je Vocal Remover of Stem Splitter.
V1 accepteert alleen audiobestanden: MP3, WAV, FLAC, M4A, AAC, OGG en WEBM. Bestanden moeten 50 MB of kleiner zijn en maximaal 600 seconden duren.
Niet in v1. Voice Isolator ondersteunt geen directe MP4/video-upload of URL ophalen. Is je bron video, extraheer dan eerst audio en upload een ondersteund audiobestand.
Voice Isolator gebruikt dezelfde audioregel als andere verwerkingsflows: 1 credit is 1 seconde bronaudio. Een opname van 90 seconden gebruikt 90 credits.
Providerindiening, providerfout en outputfinalisatie markeren de taak als failed en betalen de credits voor die opname terug. Je kunt opnieuw proberen met dezelfde of een schonere audio-export.
Nee. V1 verbetert gesproken stem in rumoerige audio, maar doet geen diarization, doelsprekerextractie, forensic restoration of scheiding van meerdere mensen die door elkaar praten.
Upload audio, vergelijk voor en na en download daarna de geïsoleerde MP3.
Eenvoudige pay-as-you-go prijzen