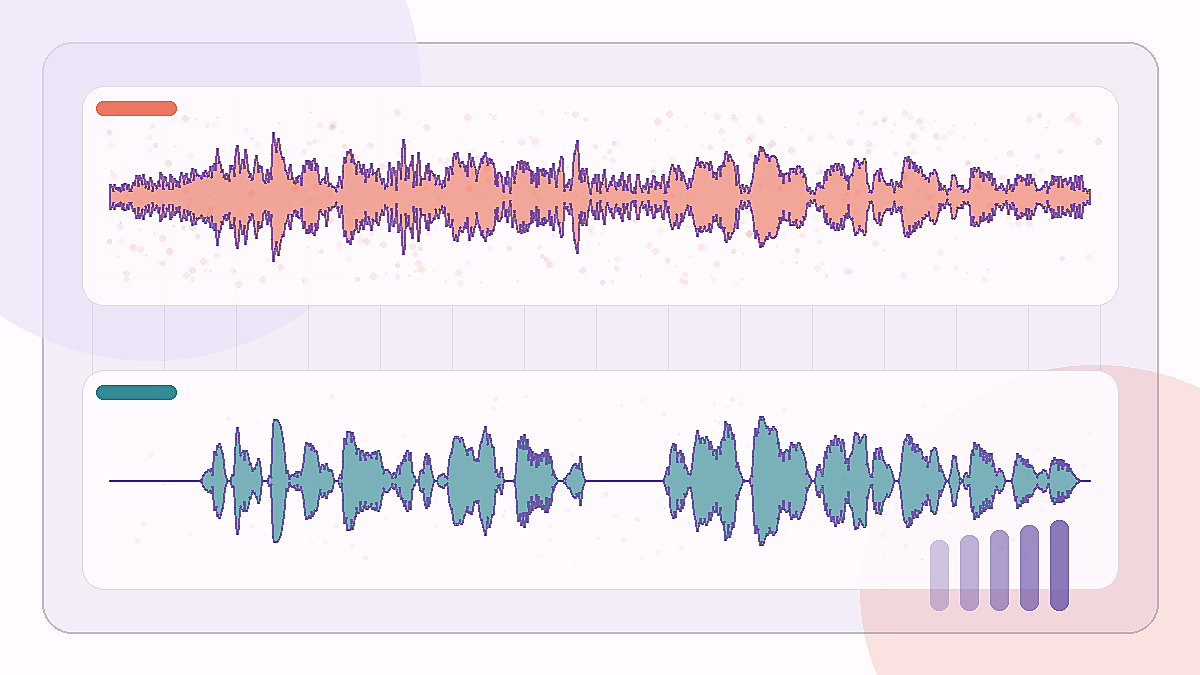
Прирост SNR: +15.0 dB
Очистка речи с шумом автобуса
Клип с низким SNR, где под фразой слышен гул, похожий на транспортный шум.
Шумный исходник
Изолированный голос
Edinburgh noisy speech · bus 2.5 dB
Есть интервью, звонок, лекция, фрагмент подкаста, полевая запись или голосовая заметка, где речь плохо слышна? Загрузите аудио и изолируйте речь в более чистый MP3.
Voice isolator отделяет человеческую речь от фонового шума в аудиозаписи. Для речи используйте его с интервью, звонками, лекциями, подкастами, полевыми записями или голосовыми заметками. Для песен и музыкального вокала используйте Vocal Remover или Stem Splitter.
Для песен и музыкального вокала используйте Vocal Remover / Stem Splitter
Только аудиозагрузка. 3 бесплатные минуты для подходящих аккаунтов. Credits возвращаются, если обработка провайдера не удалась.
Войдите, чтобы обработать аудио
Вы можете выбрать файл и прослушать его здесь, но задача Voice Isolator запускается только после входа, потому что использует платную GPU-обработку.
Исходная шумная запись
Изолированная речь
Четыре коротких noisy speech фрагмента обработаны через playmore/speech-enhancer на Replicate. Включите пары before / after, чтобы оценить очистку.
Клип с низким SNR, где под фразой слышен гул, похожий на транспортный шум.
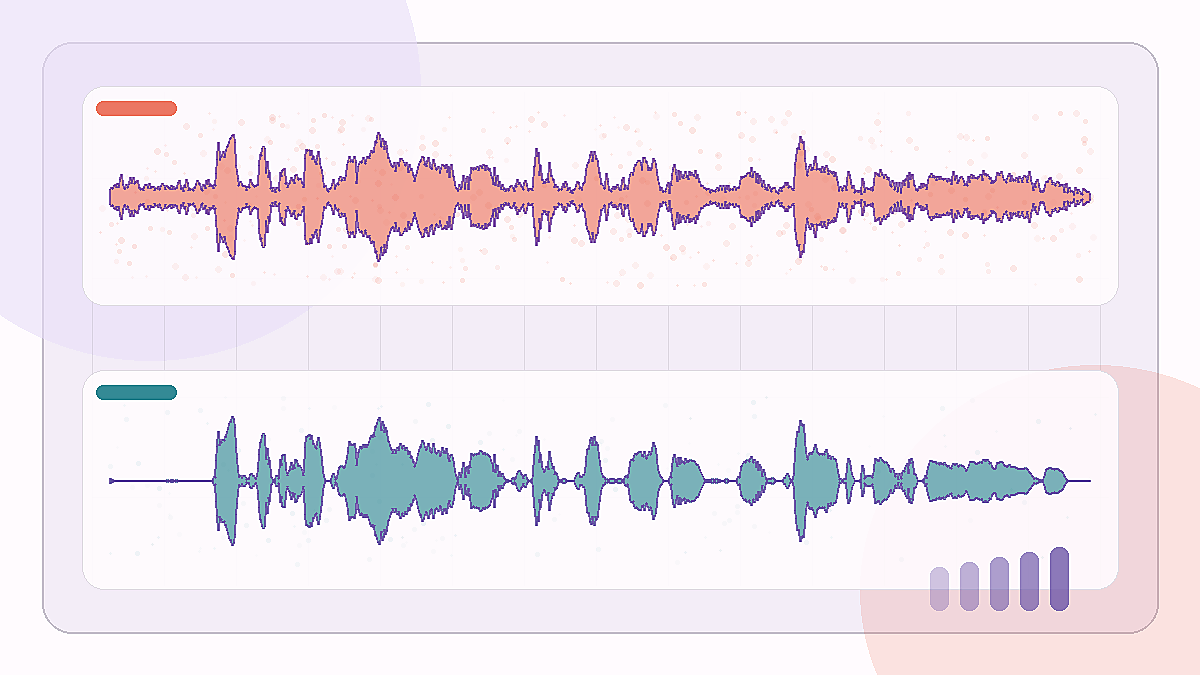
Фрагмент с фоном кафе показывает, остается ли речь понятной после снижения широкого окружающего шума.
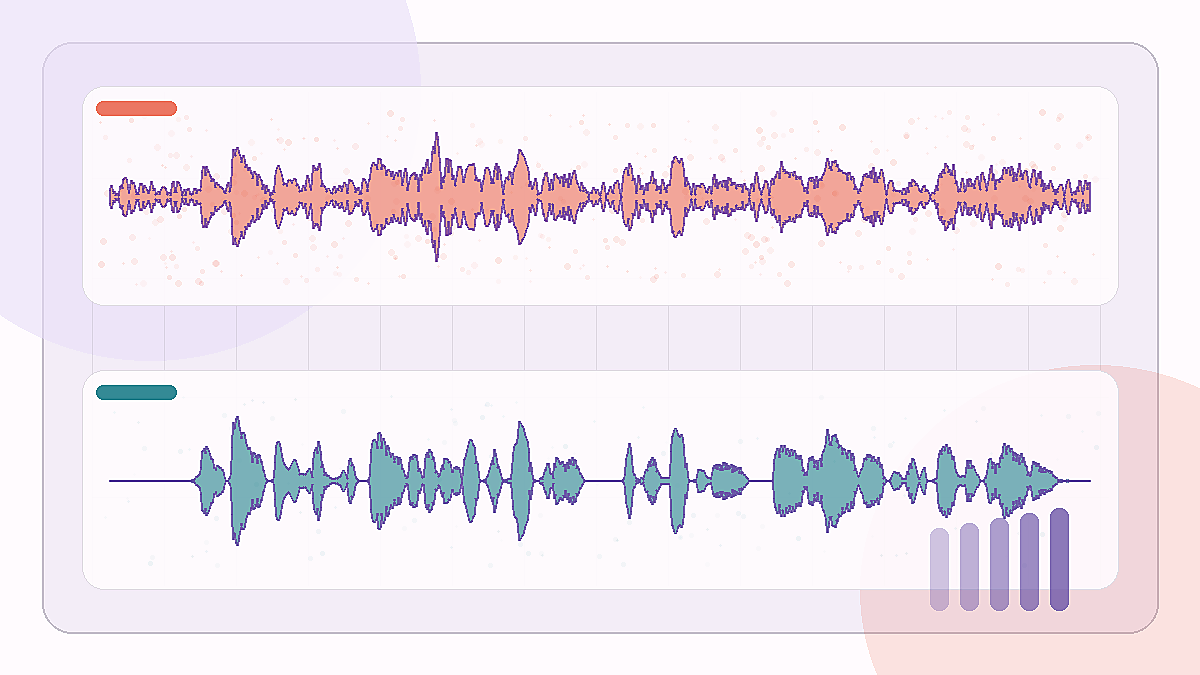
Сложная офисная запись, где нужно сохранить фразу и убрать комнатный шум.
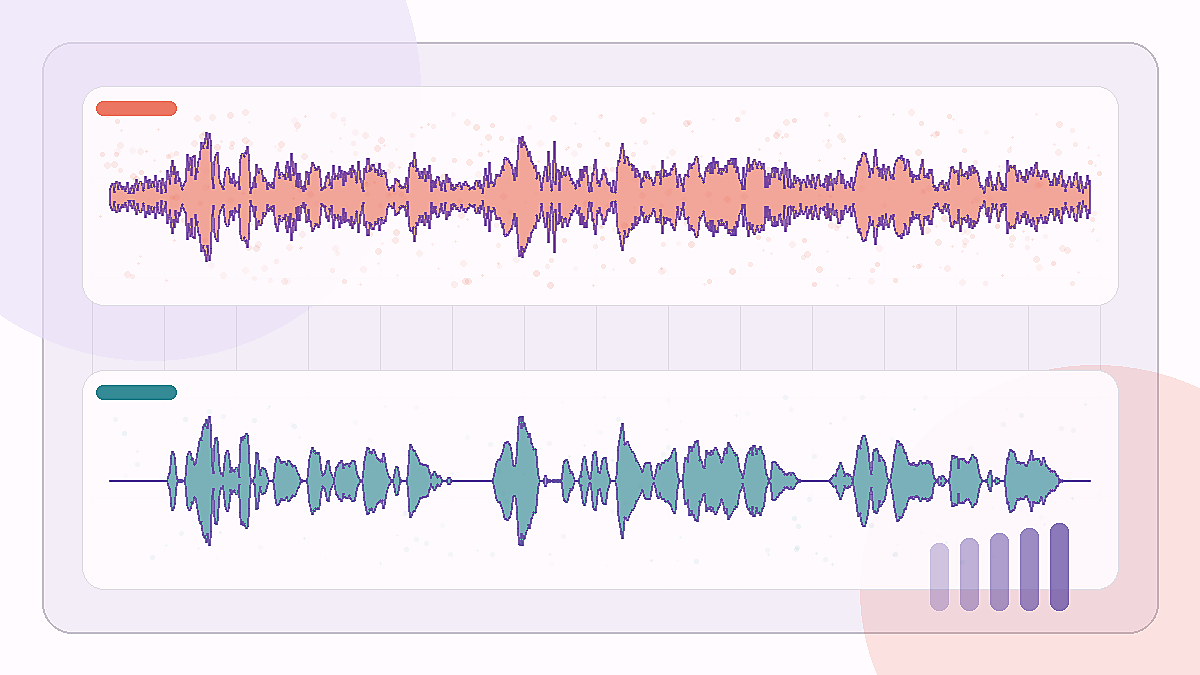
Более длинный клип с общественной площади с сильным фоном вокруг одного говорящего голоса.
Источник аудио: Cassia Valentini-Botinhao, Noisy speech database for training speech enhancement algorithms and TTS models, University of Edinburgh DataShare, CC BY 4.0. Улучшенные версии созданы с Replicate playmore/speech-enhancer.
Запрос voice isolator смешивает две задачи: очистку речи и удаление музыкального вокала. Эта страница для речи в шумных записях. Если источник — песня, караоке, acapella или музыкальный вокал, используйте Vocal Remover.
Начните с аудиофайла: MP3, WAV, FLAC, M4A, AAC, OGG или WEBM. Voice Isolator v1 принимает файлы до 50 MB и 600 секунд. Прямой MP4 upload, URL fetching и live microphone cleanup не входят в workflow.
Очистку речи нужно слышать. Используйте player before для исходной шумной записи, затем сравните ее с изолированной речью после обработки. Сравнение помогает оценить разборчивость, артефакты и готовность к скачиванию.
Результат — один MP3 с речью, а не stem package, mixer session или ZIP. Используйте его для проверки, монтажа, подготовки транскрипции, очистки подкаста или более понятной версии речевой записи.
На странице можно выбрать и прослушать файл, но платная задача запускается после входа. Voice Isolator использует 1 credit за секунду исходника. Сбой отправки провайдеру, провайдера или output finalization возвращает credits.
Voice Isolator не является real-time denoise для звонков, OBS, Discord, Zoom или Teams. Это не diarization, target-speaker extraction, forensic restoration или разделение перекрывающихся говорящих. Для видео сначала извлеките аудио.
Этот flow отделен от музыкального stem splitter. Он отправляет загруженное аудио в Replicate playmore/speech-enhancer с моделью mossformer2_se_48k, затем finalizes возвращенное аудио как isolated-voice MP3 для скачивания.
Voice Isolator извлекает речь из шумных записей: интервью, звонков, лекций, подкастов, голосовых заметок и полевого аудио. Это speech cleanup, а не music stem separation.
Нет. Эта страница для речи в шумных записях. Для песен, музыкального вокала, караоке, acapella, ремиксов или stem workflow используйте Vocal Remover или Stem Splitter.
V1 принимает только аудиофайлы: MP3, WAV, FLAC, M4A, AAC, OGG и WEBM. Файл должен быть не больше 50 MB и не длиннее 600 секунд.
Не в v1. Voice Isolator не поддерживает прямой MP4/video upload или URL fetching. Если источник — видео, сначала извлеките аудио и загрузите поддерживаемый аудиофайл.
Voice Isolator использует то же правило, что и другие аудиопроцессы: 1 credit равен 1 секунде исходного аудио. Запись 90 секунд использует 90 credits.
Сбой отправки провайдеру, провайдера и output finalization помечают задачу как failed и возвращают credits за запись. Можно повторить с тем же или более чистым аудиоэкспортом.
Нет. V1 улучшает речь в шумном аудио, но не выполняет diarization, target-speaker extraction, forensic restoration или разделение нескольких людей, говорящих одновременно.
Загрузите аудио, сравните до и после, затем скачайте изолированный MP3.
Простая оплата по мере использования