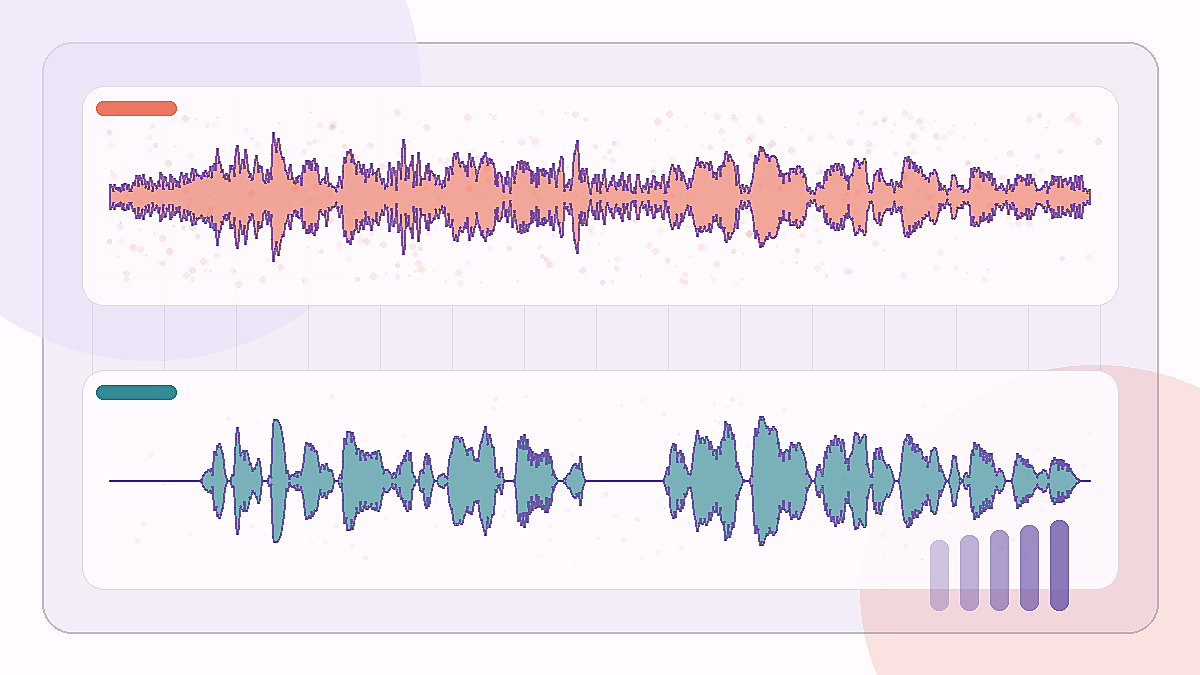
SNR 提升: +15.0 dB
公車噪聲語音清理
低信噪比公車噪聲片段,類似交通低頻噪聲壓在人聲下方的場景。
嘈雜原音
提取後人聲
Edinburgh noisy speech · bus 2.5 dB
如果採訪、通話、課程、Podcast 片段、現場錄音或語音備忘裡的 speech 聽不清,請上傳音訊,把 spoken voice 提取成更乾淨的 MP3。
Voice isolator 會從錄音的背景噪音中分離人類 speech。spoken voice 場景適合採訪、通話、課程、Podcast、現場錄音或語音備忘。歌曲和音樂人聲請改用 vocal remover 或 stem splitter。
歌曲和音樂人聲請使用 Vocal Remover / Stem Splitter
僅支援音訊上傳。符合條件的帳號有 3 分鐘免費額度。provider 處理失敗會退回 credits。
登入後處理音訊
你可以先選擇檔案並在頁面內預覽,但 Voice Isolator 任務需要登入後才會開始,因為它會使用付費 GPU 處理。
原始嘈雜錄音
提取後的 spoken voice
這 4 段短音訊都來自真實 noisy speech 資料集,並已用 Replicate 上的 playmore/speech-enhancer 處理。可以逐段播放 before / after 判斷效果。
低信噪比公車噪聲片段,類似交通低頻噪聲壓在人聲下方的場景。
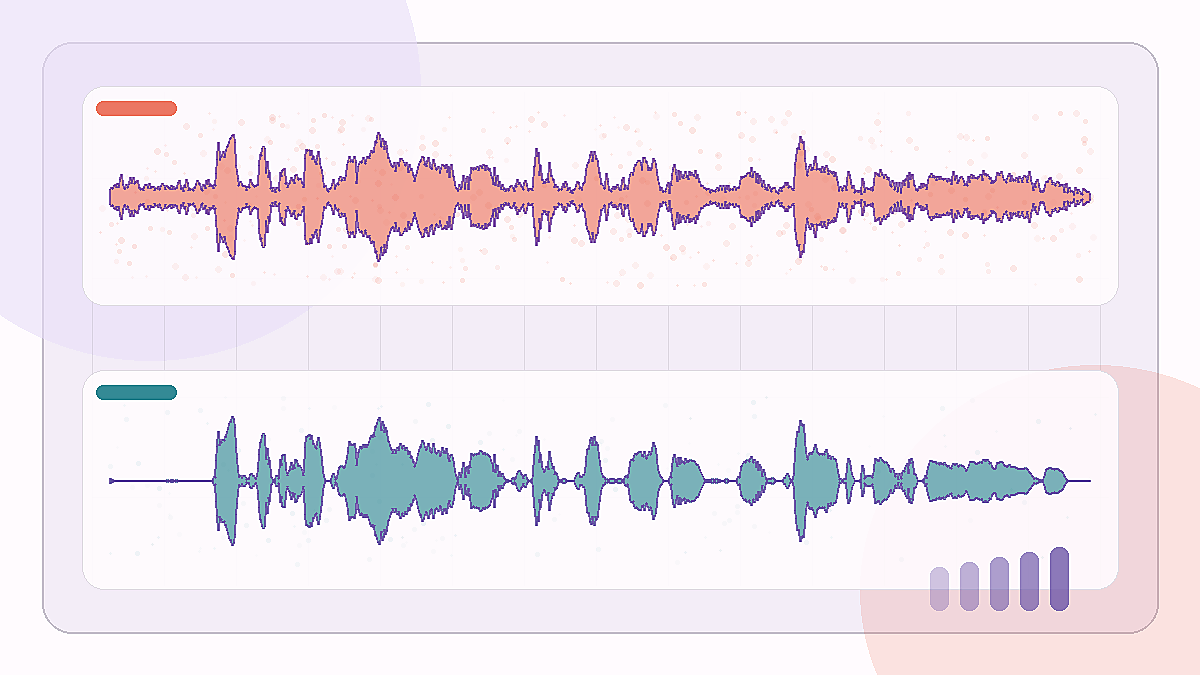
咖啡館背景噪聲樣本,用來測試降低環境聲後 spoken voice 是否仍然清楚。
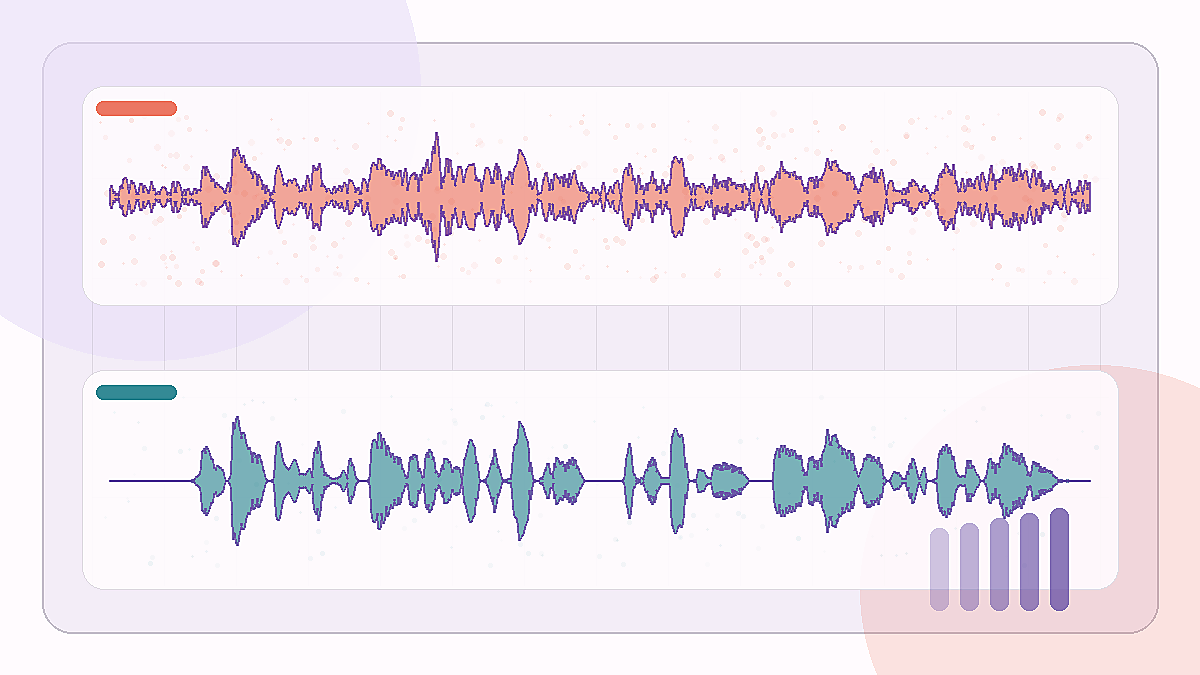
較難的辦公室噪聲錄音,需要保留句子主體,同時壓低房間底噪。
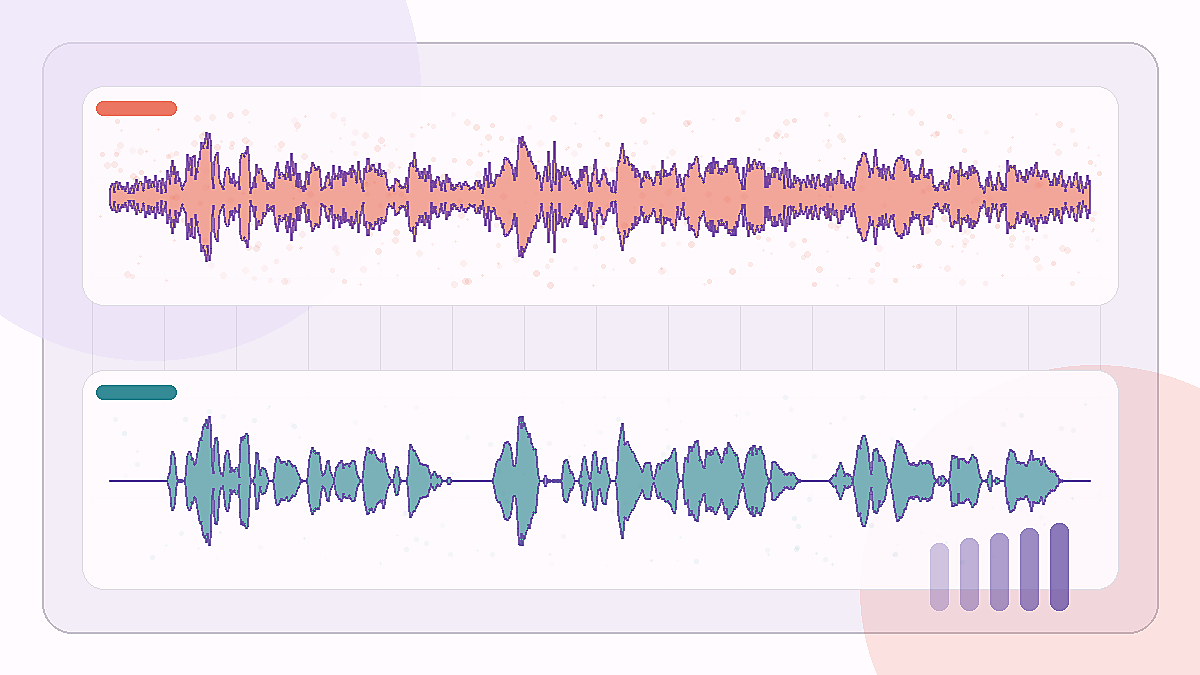
較長的公共廣場噪聲片段,背景很重,但主體是單一人聲。
音訊來源:Cassia Valentini-Botinhao, Noisy speech database for training speech enhancement algorithms and TTS models, University of Edinburgh DataShare, CC BY 4.0。增強結果由 Replicate playmore/speech-enhancer 產生。
Voice isolator 搜尋裡混著兩類需求:speech cleanup 和音樂人聲分離。本頁面面向嘈雜錄音裡的 spoken voice。如果你的來源是歌曲、卡拉 OK、acapella 或音樂人聲,請改用 Vocal Remover。
從音訊檔案開始:MP3、WAV、FLAC、M4A、AAC、OGG 或 WEBM。Voice Isolator v1 支援最大 50 MB、最長 600 秒。直接 MP4 上傳、URL 抓取和即時麥克風降噪不在此流程內。
Speech cleanup 必須聽得到。先用 before player 播放原始嘈雜錄音,再和處理後的 isolated spoken voice 對比。這個並排檢查可以幫助你判斷清晰度、artifacts,以及是否可以下載使用。
結果是一個 spoken voice MP3,不是 stem package、mixer session 或 ZIP 檔案。你可以用於複聽、編輯、轉寫準備、Podcast 清理,或分享更清楚的語音版本。
你可以在頁面上選擇並預覽檔案,但真正產生費用的任務會在登入後啟動。Voice Isolator 按每 1 秒來源音訊 1 credit 計費。provider 提交、provider 處理或輸出 finalization 失敗都會退回 credits。
Voice Isolator 不是通話、OBS、Discord、Zoom 或 Teams 的即時降噪。它也不是 diarization、目標說話人提取、forensic restoration 或重疊說話人分離。影片請先提取音訊,再上傳支援的音訊檔案。
這個流程和音樂 stem splitter 分開。它把上傳的音訊傳送到 Replicate playmore/speech-enhancer,並使用 mossformer2_se_48k model,然後把返回的音訊 finalized 為可下載的 isolated-voice MP3。
Voice Isolator 用於從採訪、通話、課程、Podcast、語音備忘和現場錄音等嘈雜錄音中提取 spoken voice。它是 speech cleanup,不是音樂 stem separation。
不能。本頁面用於嘈雜錄音裡的 spoken voice。歌曲、音樂人聲、卡拉 OK、acapella、remix 或 stem 工作流請使用 Vocal Remover 或 Stem Splitter。
V1 只接受音訊檔案:MP3、WAV、FLAC、M4A、AAC、OGG 和 WEBM。檔案必須不超過 50 MB,時長不超過 600 秒。
v1 不支援。Voice Isolator 不支援直接 MP4/video 上傳,也不支援 URL 抓取。如果來源是影片,請先提取音訊,再上傳支援的音訊檔案。
Voice Isolator 沿用音訊處理規則:1 credit 等於來源音訊 1 秒。90 秒錄音會使用 90 credits。
provider 提交失敗、provider 處理失敗和輸出 finalization 失敗都會把任務標記為 failed,並退回這段錄音使用的 credits。你可以用同一個檔案或更乾淨的匯出重試。
不能。V1 用於增強嘈雜音訊裡的 spoken voice,不做 diarization、目標說話人提取、forensic restoration,也不分離同一錄音中互相覆蓋的多個人聲。
上傳音訊,對比 before/after,然後下載 isolated MP3。