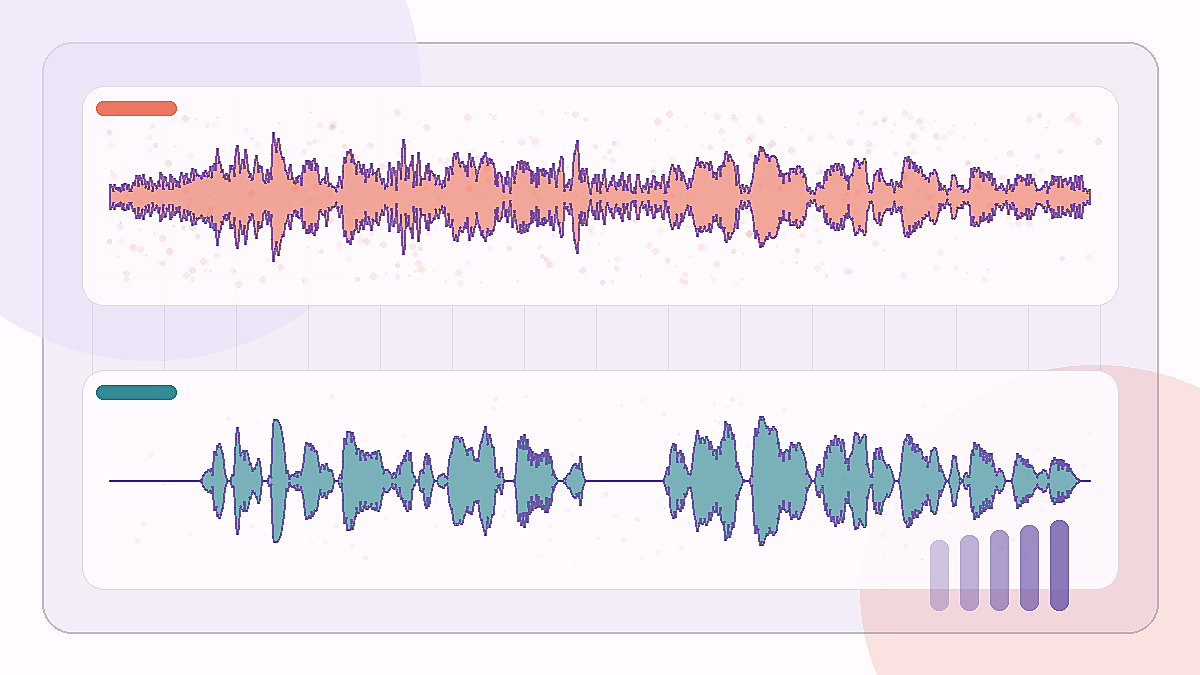
SNR 提升: +15.0 dB
公交噪声语音清理
低信噪比公交噪声片段,类似交通低频噪声压在人声下面的场景。
嘈杂原音
提取后人声
Edinburgh noisy speech · bus 2.5 dB
如果采访、通话、课程、播客片段、现场录音或语音备忘里的 speech 听不清,上传音频,把 spoken voice 提取成更干净的 MP3。
Voice isolator 会从录音的背景噪声里分离人类 speech。spoken voice 场景适合采访、通话、课程、播客、现场录音或语音备忘。歌曲和音乐人声请改用 vocal remover 或 stem splitter。
歌曲和音乐人声请使用 Vocal Remover / Stem Splitter
仅支持音频上传。符合条件的账号有 3 分钟免费额度。provider 处理失败会退回 credits。
登录后处理音频
你可以先选择文件并在页面内预览,但 Voice Isolator 任务需要登录后才会开始,因为它会使用付费 GPU 处理。
原始嘈杂录音
提取后的 spoken voice
这 4 段短音频都来自真实 noisy speech 数据集,并已用 Replicate 上的 playmore/speech-enhancer 处理。可以逐段播放 before / after 判断效果。
低信噪比公交噪声片段,类似交通低频噪声压在人声下面的场景。
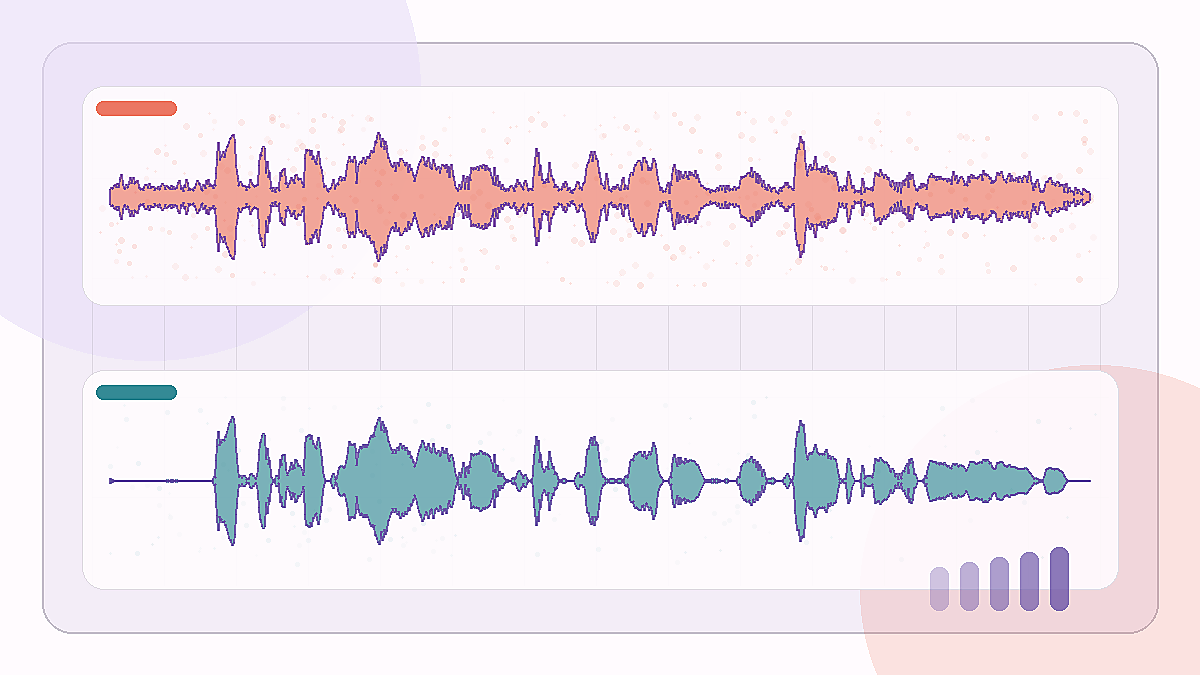
咖啡馆背景噪声样本,用来测试降低环境声后 spoken voice 是否仍然清楚。
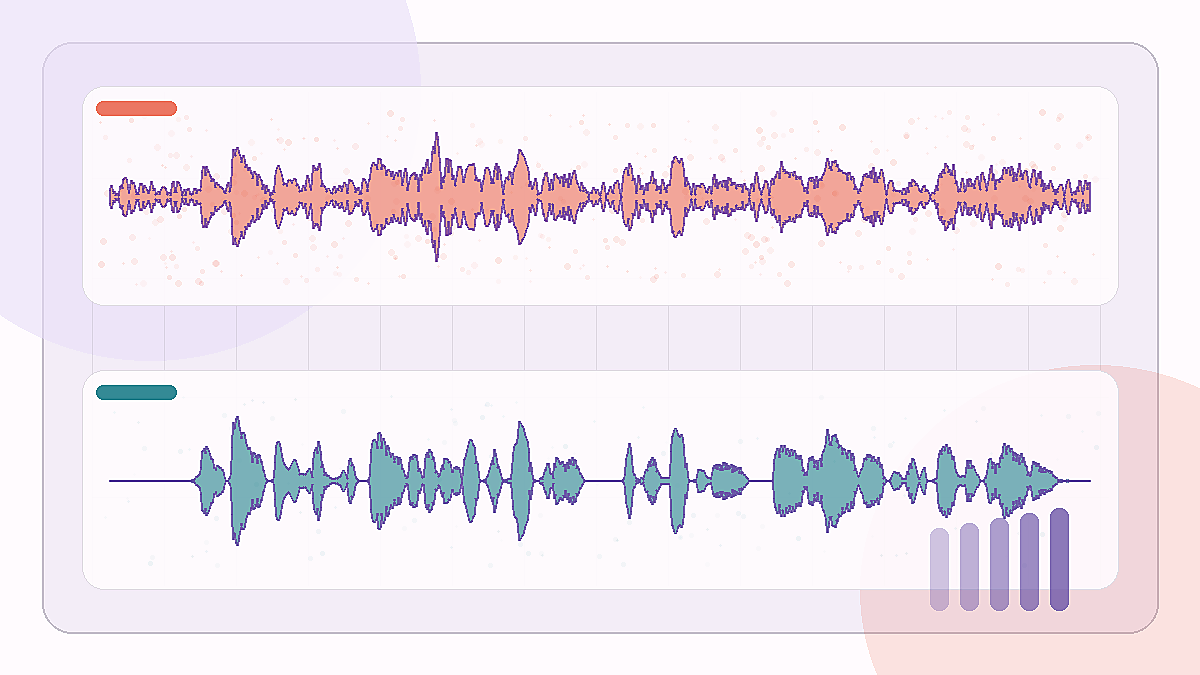
较难的办公室噪声录音,需要保留句子主体,同时压低房间底噪。
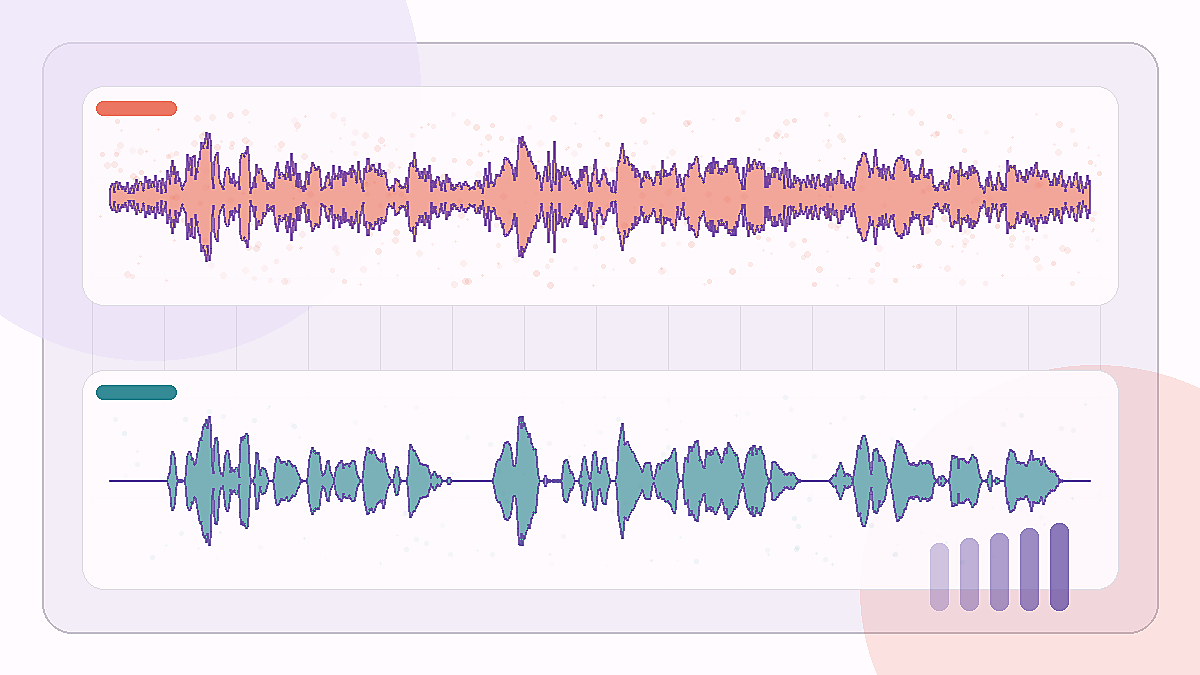
更长的公共广场噪声片段,背景很重,但主体是单个人声。
音频来源:Cassia Valentini-Botinhao, Noisy speech database for training speech enhancement algorithms and TTS models, University of Edinburgh DataShare, CC BY 4.0。增强结果由 Replicate playmore/speech-enhancer 生成。
Voice isolator 搜索里混着两类需求:speech cleanup 和音乐人声分离。本页面面向嘈杂录音里的 spoken voice。如果你的来源是歌曲、卡拉 OK、acapella 或音乐人声,请改用 Vocal Remover。
从音频文件开始:MP3、WAV、FLAC、M4A、AAC、OGG 或 WEBM。Voice Isolator v1 支持最大 50 MB、最长 600 秒。直接 MP4 上传、URL 抓取和实时麦克风降噪不在此流程内。
Speech cleanup 必须听得到。先用 before player 播放原始嘈杂录音,再和处理后的 isolated spoken voice 对比。这个并排检查可以帮助你判断清晰度、artifacts,以及是否可以下载使用。
结果是一个 spoken voice MP3,不是 stem package、mixer session 或 ZIP 文件。你可以用于复听、编辑、转写准备、播客清理,或分享更清楚的语音版本。
你可以在页面上选择并预览文件,但真正产生费用的任务会在登录后启动。Voice Isolator 按每 1 秒源音频 1 credit 计费。provider 提交、provider 处理或输出 finalization 失败都会退回 credits。
Voice Isolator 不是通话、OBS、Discord、Zoom 或 Teams 的实时降噪。它也不是 diarization、目标说话人提取、forensic restoration 或重叠说话人分离。视频请先提取音频,再上传支持的音频文件。
这个流程和音乐 stem splitter 分开。它把上传的音频发送到 Replicate playmore/speech-enhancer,并使用 mossformer2_se_48k model,然后把返回的音频 finalized 为可下载的 isolated-voice MP3。
Voice Isolator 用于从采访、通话、课程、播客、语音备忘和现场录音等嘈杂录音中提取 spoken voice。它是 speech cleanup,不是音乐 stem separation。
不能。本页面用于嘈杂录音里的 spoken voice。歌曲、音乐人声、卡拉 OK、acapella、remix 或 stem 工作流请使用 Vocal Remover 或 Stem Splitter。
V1 只接受音频文件:MP3、WAV、FLAC、M4A、AAC、OGG 和 WEBM。文件必须不超过 50 MB,时长不超过 600 秒。
v1 不支持。Voice Isolator 不支持直接 MP4/video 上传,也不支持 URL 抓取。如果来源是视频,请先提取音频,再上传支持的音频文件。
Voice Isolator 沿用音频处理规则:1 credit 等于源音频 1 秒。90 秒录音会使用 90 credits。
provider 提交失败、provider 处理失败和输出 finalization 失败都会把任务标记为 failed,并退回这段录音使用的 credits。你可以用同一个文件或更干净的导出重试。
不能。V1 用于增强嘈杂音频里的 spoken voice,不做 diarization、目标说话人提取、forensic restoration,也不分离同一录音中互相覆盖的多个人声。
上传音频,对比 before/after,然后下载 isolated MP3。